library(tidyverse)
set.seed(42)
n <- 50
df <- tibble( # like data.frame, but columns can be functions of preceding
x1 = rnorm(n),
x2 = rnorm(n, mean = 2, sd = 1),
x3 = rexp(n, rate = 1),
x4 = x2 + rnorm(n, sd = .1), # correlated with x2
y = x1 * 3 + x2 / 3 + rnorm(n, sd = 0.5) # function of x1 and x2 only
)Lecture 4: Model Selection
Learning Objective
By the end of this lecture, you should be able to:
- Define and differentiate between expected test error and risk
- Choose amongst metrics and estimators for model selection on a variety of problems
- Identify when a validation-set estimator of risk is biased or (nearly) unbiased
- Perform cross-validation to perform variable selection in linear regression
Motivation
We are now going to fill in the remaining steps of the learning procedure from a statistical perspective. We’ve already covered defining the statistical model, hypothesis class, estimation, and prediction.
| Step | CS Perspective | Statistical Perspective | Example: Linear Regression |
|---|---|---|---|
| 1 | Split data into train/test/val | ??? | ??? |
| 2 | Predictive Model | Hypothesis Class | \(\hat f(X) = X^\top \hat\beta\) |
| 3 | Training | Estimation | \(\hat{\beta}_\mathrm{ERM} = \hat{\beta}_\mathrm{OLS} = (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{Y}\) |
| 4 | Validation | ??? | ??? |
| 5 | Iteration | ??? | ??? |
| 6 | Testing | Prediction | \(\hat{Y}_\mathrm{new} = X_\mathrm{new}^\top \hat{\beta}\) |
- From a statistical perspective, steps 1, 4, and 5 blur together in a procedure we call model selection.
- At a high level, the purpose of these three steps is to choose the best predictive model given our training data.
Defining “The Best Model”
Before defining what we mean by “best,” let’s recall the setup from the previous lectures:
- We have an i.i.d. training dataset \(\mathcal D = \left\{ (X_i, Y_i) \right\}_{i=1}^n\) and we have chosen a loss function \(L(Y, \hat f(X))\).
- Using \(\mathcal D\), we performed empirical risk minimization (ERM) to obtain a trained model \(\hat f_{\mathcal D}\) from our hypothesis class \(\mathcal H\) by minimizing the average loss over the training data: \[ \hat f_\mathcal{D} := \mathrm{argmin}_{\hat f \in \mathcal H} \; \frac{1}{n} \sum_{i=1}^n L(Y_i, \hat f(X_i)). \]
- In this lecture, we’ll write the trained model as \(\hat f_\mathcal{D}\): the subscript \(\mathcal D\) emphasizes that it was estimated using the particular training set \(\mathcal D\) (a dependence that is central to model selection as well as the material we will cover in the next lecture).
Possible Metrics for “Best Model”
Expected test error
As in the previous two lectures, imagine drawing a fresh pair \((X_\mathrm{new}, Y_\mathrm{new})\) from the same distribution as our training data, independent of \(\mathcal D\).
The expected test error is the average loss our trained model \(\hat f_\mathcal{D}\) incurs on such a point: \[ \mathrm{Err}_\mathcal{D} := \mathbb E \left[ L(Y_\mathrm{new}, \hat f_\mathcal{D}(X_\mathrm{new})) \mid \mathcal D \right] \]
Note that the training set \(\mathcal D\) is fixed: we average only over the randomness in the new point \((X_\mathrm{new}, Y_\mathrm{new})\), not over the randomness in \(\mathcal D\).
Intuition: your boss hands you training set \(\mathcal D\), and you train a \(\hat f_\mathcal{D}\) that’s going to be deployed for a very very long time. \(\mathrm{Err}_\mathcal{D}\) estimates the error you’ll get on the many many predictions that will be made by your model.
Risk
Risk, which is one level more abstract than expected test error, averages over all sources of randomness: \[ \mathcal R := \mathbb E \left[ L \left( Y_\mathrm{new}, \hat f_{\mathcal D}(X_\mathrm{new}) \right) \right] \]
Note that all sources of randomness includes the new point \((X_\mathrm{new}, Y_\mathrm{new})\) as well as the training dataset \(\mathcal D\).
We can relate \(\mathcal R\) to the expected test error via:
\[ \mathcal R = \mathbb E \left[ \mathrm{Err}_\mathcal{D} \right] \]
Why?
Tower rule!!!
\[\begin{align*} \mathcal R &= \mathbb E \left[ L \left( Y_\mathrm{new}, \hat f_{\mathcal D}(X_\mathrm{new}) \right) \right] \\ &= \mathbb E \left[ \mathbb E \left[ L \left( Y_\mathrm{new}, \hat f_{\mathcal D}(X_\mathrm{new}) \right) \mid \mathcal D \right] \right] \\ &= \mathbb E \left[ \mathrm{Err}_\mathcal{D} \right] \end{align*}\]
Intuition: if you were to get a new training set \(\mathcal D'\) and retrain your model, how well would it perform on average?
In a Perfect World, Which Metric Should We Use?
Let’s ignore the fact that we have access to limited amounts of data, and pretend that it was possible to (exactly) compute expected test error and risk. Which one should we use?
In general I would argue that risk is actually the metric we care most about.
NoteExpected Test Error vs. Risk
Reasons to prefer expected test error
- In practice, we only have one training set \(\mathcal D\).
- Expected test error tells us how well our model will perform on the particular training set we are given.
Reasons to prefer risk
- In practice, we might get new data to retrain our model on; we don’t want a metric that’s dependent on a particular training set.
- If we’re trying to select a “best” model, we’d ideally like one that’s not too sensitive to the particular training set we happened to get.
- As we will see next lecture, risk is easier to analyze theoretically.
- In 75% of scenarios, it doesn’t matter if we target risk or expected test error. (In practice, most estimators of risk are also estimators of expected test error, and vice versa.) However, we’ll see some cases (e.g. on Homework 2) where the distinction matters.
Estimating Risk
Bad Idea: Training Error
A common mistake is to use training error as an estimator of risk:
\[ \widehat{\mathrm{Err}}_\mathrm{train} := \frac{1}{n} \sum_{i=1}^n L(Y_i, \hat f_\mathcal{D}(X_i)) \]
Training error is almost always a severely biased estimator of risk, and should never be used for model selection.
Why?
- The training error is computed on the same data that was used to train the model.
- Therefore, the model has “seen” this data before, and has likely fit it quite well.
- In contrast, risk is computed on new, unseen data.
- As a result, training error underestimates the true risk of the model.
- The training error is computed on the same data that was used to train the model.
(Training error does indeed have its uses; we’ll see one example next lecture!)
Ideal Solution: Many Samples of Training Data + One Test Point
Imagine we had access to a generator that produces random \(\left\{ (X_i, Y_i) \right\}_{i=1}^{n+1}\) samples, where the \(n+1\) pairs are i.i.d.
We could estimate risk by:
Generating \(m\) samples \(\left\{ \left\{ (X_i^{(j)}, Y_i^{(j)}) \right\}_{i=1}^{n+1} \right\}_{j=1}^{m}\)
Estimate risk as: \[ \hat{\mathcal R} := \frac{1}{m} \sum_{j=1}^m L_j, \quad L_j = L\left( Y_{n+1}^{(j)}, \hat f_{\mathcal D^{(j)}}( X^{(j)}_{n+1}) \right), \quad \mathcal D^{(j)} = \left\{ (X_i^{(j)}, Y_i^{(j)}) \right\}_{i=1}^n. \]
- In other words, for each of the \(m\) samples, we train a model on the first \(n\) data points, and compute its loss on the \(n+1^\mathrm{th}\) datapoint we withhold from training.
- Because all \(n+1\) pairs are i.i.d. from the same distribution, the withheld point \((X_{n+1}, Y_{n+1})\) is identically distributed to the new point \((X_\mathrm{new}, Y_\mathrm{new})\) from our definition of risk: it plays exactly the same role, a fresh draw that the model did not train on.
By the law of large numbers, as \(m \to \infty\) we have:
\[\hat{\mathcal R} \to \mathbb E[ L( Y_{n+1}, \hat f_\mathcal{D}( X_{n+1}) )] = \mathbb E[ L( Y_\mathrm{new}, \hat f_\mathcal{D}( X_\mathrm{new}) )] = \mathcal R\]
Practical Solution: Cross-Validation
- In practice, we only have access to a single dataset \(\mathcal D = \left\{ (X_i, Y_i) \right\}_{i=1}^n\) with \(n\) data points.
- Nevertheless: we can approximate the ideal solution above using leave-one-out cross-validation (LOO-CV).
TipCross Validation
- Given: a single dataset \(\mathcal D = \left\{ (X_i, Y_i) \right\}_{i=1}^n\)
- For each \(i = 1, \ldots, n\):
- Train a model \(\hat f_{\mathcal D_{-i}}\) on the dataset with the \(i^\mathrm{th}\) point removed: \(\mathcal D_{-i} := \left\{ (X_j, Y_j) \right\}_{j \neq i}\)
- Compute the loss on the withheld point: \(L_i := L(Y_i, \hat f_{\mathcal D_{-i}}(X_i))\)
- Estimate risk as: \(\hat{\mathcal R}_\mathrm{LOOCV} := \frac{1}{n} \sum_{i=1}^n L_i\)
Why Does LOO-CV Work?
To reason about cross-validation, it is helpful to make explicit the size of the training set. Let \(\mathcal R_m\) denote the risk of a model trained on \(m\) i.i.d. data points; under this notation, the risk of a model trained on our full dataset is \(\mathcal R = \mathcal R_n\).
Each \(L_i\) is an unbiased estimate of risk on a training set of size \(n-1\):
\[\begin{align*} \mathbb E[L_i] &= \mathbb E \left[ L(Y_i, \hat f_{\mathcal D_{-i}}(X_i)) \right] =: \mathcal R_{n-1} \\ \end{align*}\]
By linearity of expectation, we also have that \(\hat{\mathcal R}_\mathrm{LOOCV}\) is an unbiased estimate of risk on a training set of size \(n-1\):
Derivation:
\[\begin{align*} \mathbb E[\hat{\mathcal R}_\mathrm{LOOCV}] = \mathbb E \left[ \frac{1}{n} \sum_{i=1}^n L_i \right] = \frac{1}{n} \sum_{i=1}^n \mathbb E[L_i] = \mathcal R_{n-1} \end{align*}\]
Unlike our “ideal estimator” above, the \(L_i\) are not independent, and therefore we can’t apply the law of large numbers to conclude that \(\hat{\mathcal R}_\mathrm{LOOCV}\) converges to \(\mathcal R\).
In practice, however, \(\hat{\mathcal R}_\mathrm{LOOCV}\) is often a good estimator of risk.
A More Efficient Solution: K-Fold Cross Validation
- LOO-CV requires training \(n\) separate models, which can be very expensive.
- A more efficient alternative is K-fold cross validation (K-CV):
TipK-Fold Cross Validation
- Given: a single dataset \(\mathcal D = \left\{ (X_i, Y_i) \right\}_{i=1}^n\)
- Randomly split \(\mathcal D\) into \(K\) (roughly) equal-sized “folds”: \(\mathcal D_1, \ldots, \mathcal D_K\)
- For each \(k = 1, \ldots, K\):
- Train a model \(\hat f_{\mathcal D_{-k}}\) on the dataset with the \(k^\mathrm{th}\) fold removed: \(\mathcal D_{-k} := \bigcup_{j \neq k} \mathcal D_j\)
- Compute the loss on the withheld fold: \(L_k := \frac{1}{|\mathcal D_k|} \sum_{(X_i, Y_i) \in \mathcal D_k} L(Y_i, \hat f_{\mathcal D_{-k}}(X_i))\)
- Estimate risk as: \(\hat{\mathcal R}_\mathrm{K-CV} := \frac{1}{K} \sum_{k=1}^K L_k\)
Decreasing \(K\) decreases the number of models we need to train.
However, decreasing \(K\) also results in a worse estimator of risk.
Why?
Intuitively: as \(K\) decreases, each model is trained on less data, and we’re trying to estimate the risk of a model trained on all \(n\) data points.
Formally: each \(L_k\) is an unbiased estimate of risk on a training set of size \(n - n/K\), but the difference between \(\mathcal R_n\) and \(\mathcal R_{n - n/K}\) can be significant for small \(K\).
Model Selection (Finally!)
Now that we’ve chosen risk as our metric for “the best model,” model selection amounts to choosing the predictive model with the best risk.
TipModel Selection
- Given: a single dataset \(\mathcal D\)
- For however long you have,
- Propose a model (hypothesis class + estimation procedure)
- Estimate its parameters on \(\mathcal D\) to get \(\hat f_\mathcal{D}\)
- Estimate its risk \(\hat{\mathcal R}\) using K-CV (or some other method)
- Choose the model with the lowest estimated risk \(\hat{\mathcal R}\)
Example: Variable Selection
Consider the following synthetic dataset, where we have:
\[ Y = 3 X_1 + \frac{1}{3} X_2 + \varepsilon, \quad \varepsilon \sim \mathcal N(0, 0.5^2) \]
Note that \(Y\) is a function of \(X_1\) and \(X_2\) only, and \(X_3\) and \(X_4\) are irrelevant to predicting \(Y\).
We might consider the following models (here written with linear regression notation):
- Model 1: \(f(X) = \beta_0 + \beta_1 X_1\)
- Model 2: \(f(X) = \beta_0 + \beta_1 X_1 + \beta_2 X_2\)
- Model 3: \(f(X) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3\)
- Model 4: \(f(X) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 + \beta_4 X_4\)
TipVariable Selection is a Specific Instance of Model Selection
You might recognize this setup as a variable selection problem. (Even more specifically, these model choices may remind you of forward stepwise selection from STAT 306). Adding covariates to our regression changes the hypothesis class of predictors we consider.
Note that model selection is a much broader concept than variable selection. For example, we might also consider:
\[f(X) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 + \beta_4 X_4 + \beta_5 X_1^2\]
This predictive model doesn’t add any new covariates, but it does change the hypothesis class we are considering.
Let’s fit each of these models with ERM, and use 5-fold cross validation to estimate the risks of the ERM-fitted models:
library(cv) # NOTE: you can't use this package on Homework 1
# but for sure use it on your own projects!
model1 <- lm(y ~ x1, data = df)
model2 <- lm(y ~ x1 + x2, data = df)
model3 <- lm(y ~ x1 + x2 + x3, data = df)
model4 <- lm(y ~ x1 + x2 + x3 + x4, data = df)
risks <- tibble(
model = c("Model 1", "Model 2", "Model 3", "Model 4"),
risk = c(
cvInfo(cv(model1, k = 5, criterion = mse)),
cvInfo(cv(model2, k = 5, criterion = mse)),
cvInfo(cv(model3, k = 5, criterion = mse)),
cvInfo(cv(model4, k = 5, criterion = mse))
)
)
risks %>%
ggplot(aes(x = model, y = risk)) +
geom_col() +
labs(title = "Estimated Risk by Model", y = "Estimated Risk (MSE)", x = "Model") +
theme_minimal()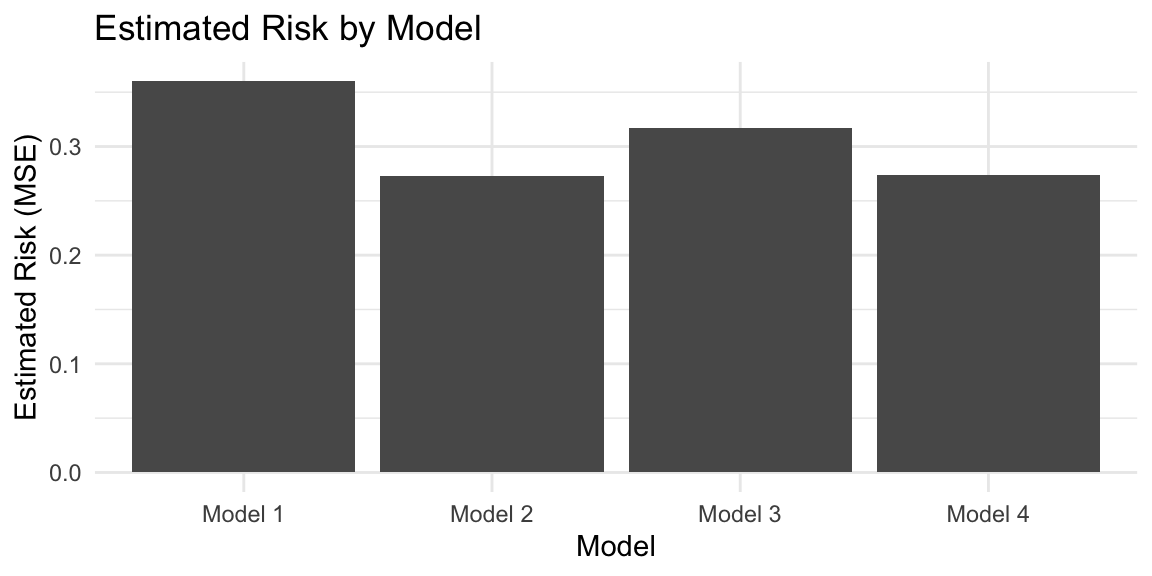
Based on our model selection procedure (using 5-fold CV to estimate risk), we would choose Model 2, which—in this case—is indeed the correct model!
Connection to the Algorithmic Perspective
- Step 1 train/test/val split: the train/val split is implicit in K-fold CV, and the test set is used only at the very end to estimate test error of the final model. (Do not touch the test set until the very end!)
- Step 4 validation: here is where we actually estimate risk using K-fold CV.
- Step 5 iteration: we iterate over different predictive models, estimating their risk using K-fold CV, and performing model selection along the way (i.e. refining our predictive model in ways to reduce risk).
Summary
- Model selection is the process of choosing the “best predictive model” given our training data.
- We can define “best” in terms of expected test error, or risk. In practice, risk is often the most appropriate metric.
- We can estimate risk using cross-validation. (We will see other estimators later in the course.)
- Never use training error to select models!