[1] 1[1] 3 4[1] 4 3 1[1] 1 3 4 1 3 4{tidyverse}
Today is going to be a whirlwind tour of R.
If you are new to R: read the first 4 chapters of Data Science: A First Introduction.
It’s available for free at https://datasciencebook.ca. It covers:
.csv, Excel, database, and web sources.csv filestidyverse functionsggplothist functionList of 6
$ breaks : num [1:14] -3 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 ...
$ counts : int [1:13] 4 21 41 89 142 200 193 170 74 38 ...
$ density : num [1:13] 0.008 0.042 0.082 0.178 0.284 0.4 0.386 0.34 0.148 0.076 ...
$ mids : num [1:13] -2.75 -2.25 -1.75 -1.25 -0.75 -0.25 0.25 0.75 1.25 1.75 ...
$ xname : chr "rnorm(1000)"
$ equidist: logi TRUE
- attr(*, "class")= chr "histogram"[1] "histogram"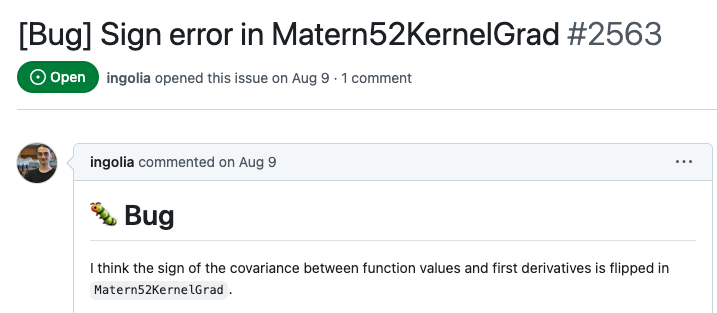
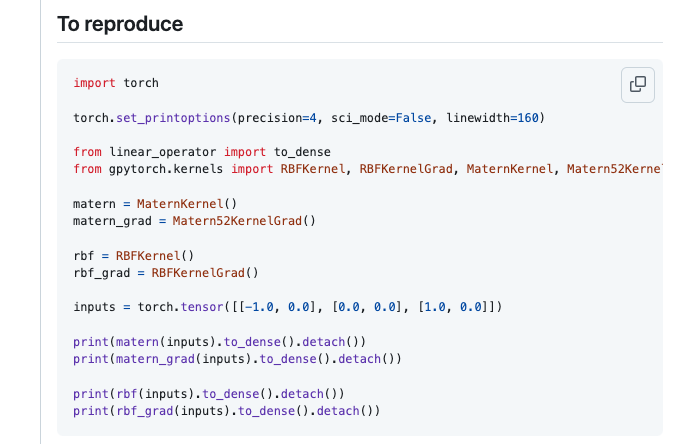
Read the first 4 chapters (especially 3 and 4!)







