Principled Peeking in A/B Testing
Contents
Principled Peeking in A/B Testing¶
)
Image from Unsplash by Pawel Szvmanski and Unlocking Peeking in AB-Tests by Dennis Meisner
Overview¶
In the previous chapter we examined the early peeking problem using a simulation study. We noticed that although classical tests can be used in A/B testing problems, those tests are designed for a fixed sample size. Analyzing a sample smaller than planned and stopping the experiment based on early results seriously inflates the type I error rate of the experiment. The goal of this chapter is to introduce some basic techniques of principled peeking.
Important
Stopping an experiment and rejecting \(H_0\) as soon as an observed \(p\)-value is below the specified significance level can drastically inflate the type I error rate
Sequential testing¶
Sequential tests are decision rules that allows users to test data sequentially as data come in:
The experiment may be stopped earlier, meaning the sample size is dynamic, rather than fixed
Many tests (a.k.a., multiple comparisons) are performed (sequentially)
Caution
If you make lots of comparisons, the error rates are inflated!!
There are different classes of sequential approaches:
Definition
Group sequential designs: the analyst pre-specifies when to inspect the data (interim analysis) and performs each analysis as a fixed sample one.
Full sequential designs: the analyst performs an analysis after every new observation, sequentially, in a principled way.
New platforms allow users to test data sequentially as data come in:
Users are monitoring results as they collect data and are making decisions accordingly
Users need to adaptively determine the sample size of the experiments
There are large opportunity costs associated with longer experiments
When done correctly, stopping an experiment earlier (or re-designing it) can be beneficial
Principled Peeking¶
Can we control the risk of wrongly rejecting the null hypothesis in A/B testing when early peeking and stopping is desired?
Many methods have been proposed to address this problem in the context of A/B testing experimental designs:
A basic way to control the type I error rate inflation in multiple testing problems is to adjust the p-value. For example, p-values (or critical values) can be adjusted using a Bonferroni corection.
Some new methods propose using a different test statistics and computing \(p\)-values differently. For example, in the Optimizely platform, a mixture sequential probability ratio test (mSPRT) is performed and always valid \(p\)-values are constructed.
Important
With a principled peeking approach, the significance level of each interim analysis is set at a level that controls the Type I error rate, even if the experiment is stopped earlier.
Bonferroni¶
Although originally designed for independent tests, Bonferroni correction can be used to control the type I error rate in A/B testing
Bonferroni’s correction can be thought as:
an adjustment of the \(p\)-values, multiplying them by the number of comparisons, and keeping the significance level at a desired threshold, or
an adjustment of the significance threshold \(\alpha\), dividing it by the number of comparisons, and using raw p-values, or
(an adjustment of) the critical value, computed with a sampling distribution, corresponding to the adjusted significance threshold
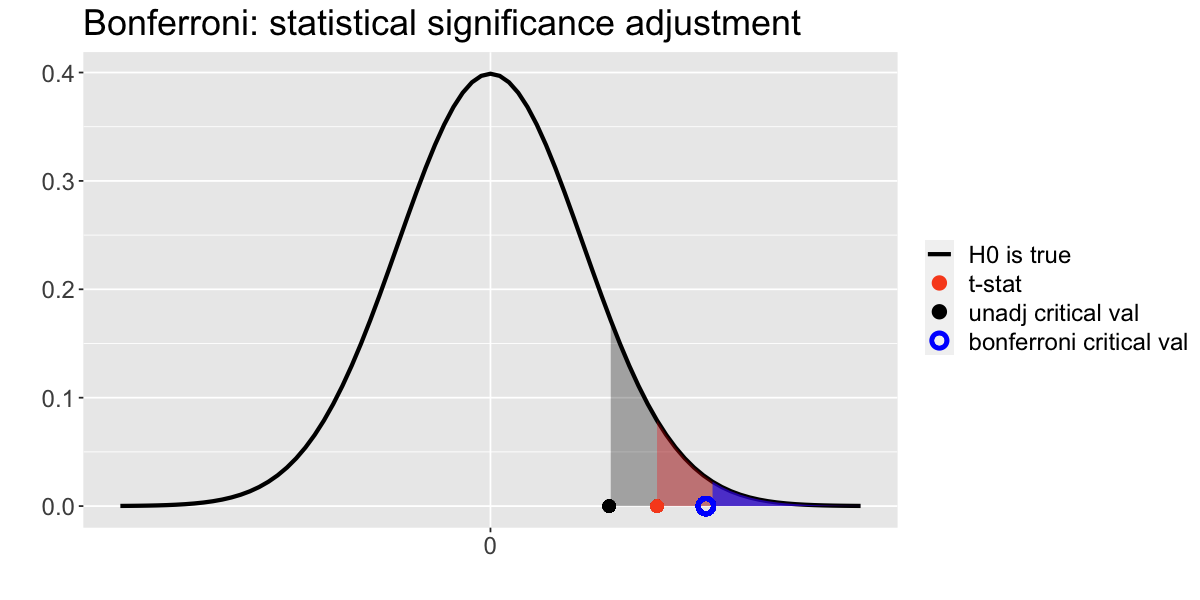
Interpretation¶
You can compare the observed t-statistic with the critical value obtained from the sampling distribuiton to test the null hypothesis:
Unadjusted test: Since the test-statistic (red dot) is greater than the (unadjusted) critical value (black dot), we have evidence to reject the null hypothesis.
Bonferroni adjusted test: Since the test-statistic (red dot) is smaller than the Bonferroni adjusted critical value (blue dot), we do not have enough evidence to reject the null hypothesis.
Alternatively, you can compare the \(p\)-value with the pre-set significance level to test the null hypothesis:
Unadjusted test: Since the \(p\)-value (red area) is smaller than the (unadjusted) significance level (grey area), we have evidence to reject the null hypothesis.
Bonferroni adjusted test: Since the \(p\)-value (red area) is larger than the Bonferroni adjusted significance level (blue area), we do not have enough evidence to reject the null hypothesis.
Hint
Note that you can also adjust the \(p\)-value of a test using a Bonferroni correction!
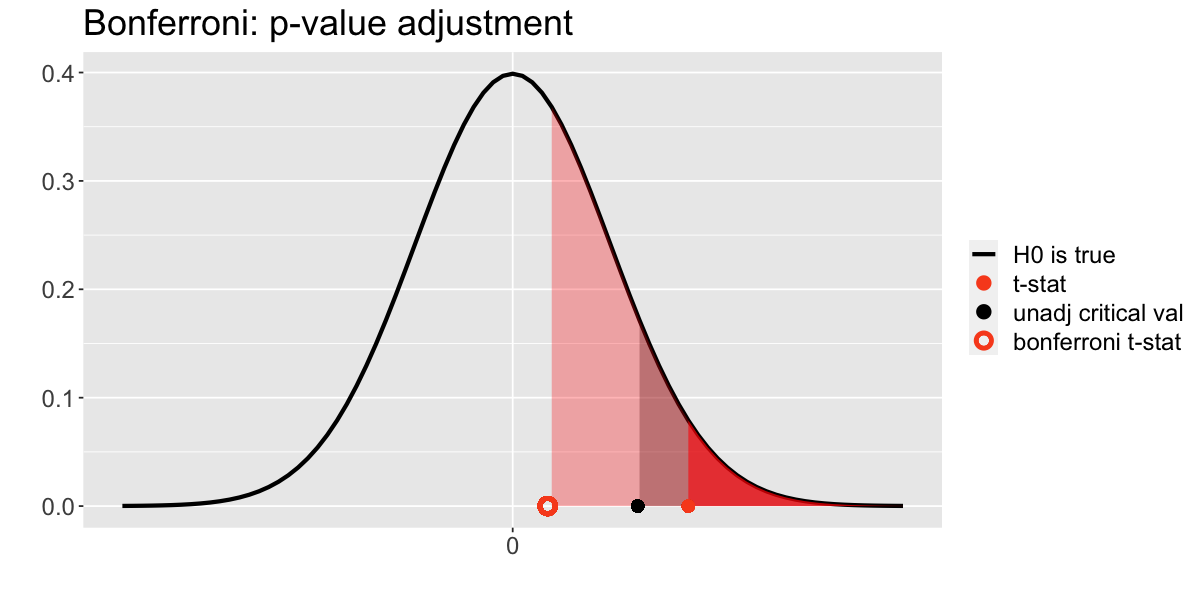
Since the adjusted \(p\)-value (light red area) is larger than the significance level (grey area), we do not have enough evidence to reject the null hypothesis.
Caution
The solid red area corresponds to the unadjusted \(p\)-value.
A/A Testing (again)¶
To examine if the Bonferroni’s correction effectively controls the type I error rate, we will use again the A/A experimental design
Important
We know that the (true) effect size is 0 in an A/A experiment!
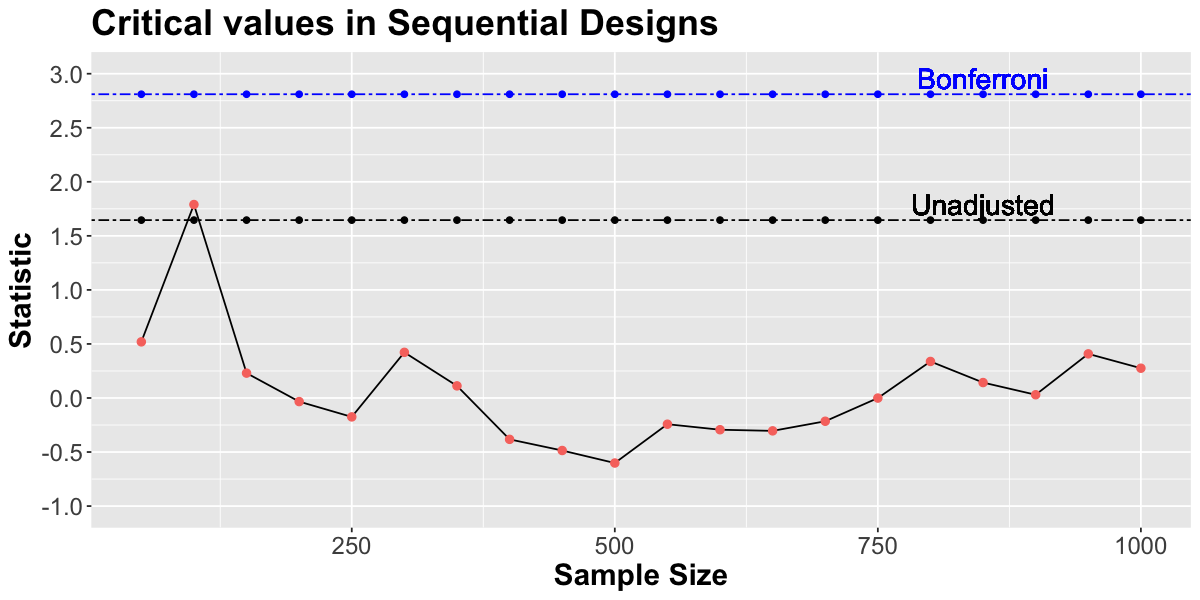
Interpretations of Bonferroni correction¶
In one A/A testing simulated experiment, using unadjusted quantities:
you would reject \(H_0\): the observed (unadjusted) t-statistic is bigger than the (unadjusted) critical value
Using Bonferroni’s adjusted quantities:
you would fail to reject \(H_0\): the observed (unadjusted) t-statistic is smaller than the (adjusted) critical value
Important
The Bonferroni’s adjusted critical value is larger than the unadjusted one: the test is more conservative! With the adjustment, we erroneously reject \(H_0\) less often!! it controls the type I error rate!!
Pocock’s boundaries¶
Other methods can be used to control the type I error rate in A/B testing experiments with early stops.
The Pocock method computes a common critical value for all interim analyses.
the Pocock’s boundary is not an adjustment of the quantile of a \(t\)-distribution
we can easily get the critical values for this design using
gsDesign::gsDesign()
Remarks
Note 1: gsDesign() outputs a full sequential design. You can read more about this package here
Note 2: a caveat about this package is that two-sample tests are based on \(z\)-statistics. However, results are nearly equivalent to a \(t\)-test. More can be read here
A/A Testing (again)¶
To examine if the Pocock method effectively controls the type I error rate, we can use again the A/A experimental design
Important
We know that the (true) effect size is 0 in an A/A experiment!
# Run this cell to get a Pocock design!
library(gsDesign)
design_pocock <- gsDesign(k = 20, #number of interim analysis planned
test.type = 1, # for one-sided tests
delta = 0, # default effect size
alpha = 0.05, #type II error rate
beta = 0.2, # type II error rate
sfu = 'Pocock')
crit_pocock <- design_pocock$upper$bound

Interpretations of Pocock correction¶
In one A/A testing simulated experiment, using unadjusted quantities:
you would reject \(H_0\): the observed (unadjusted) t-statistic is bigger than the (unadjusted) critical value
Using Pocock’s critical values:
you would fail to reject \(H_0\): the observed (unadjusted) t-statistic is smaller than the (adjusted) critical value
Important
The Bonferroni’s adjusted critical value is larger than Pocock’s critical values: the Bonferroni test is the most conservative test. Pocock method gives some control of the type I error rate!! Bonferroni gives a more conservative control of the type I error rate!!
O’Brien-Fleming’s boundaries¶
Another method available in gsDesign is the O’Brien-Fleming method
Unlike previous methods, the O’Brien-Fleming method uses non-uniform boundaries
the test has conservative critical values for earlier interim analyses and less conservative values (closer to the unadjusted critical values) as more data are collected
design_of <- gsDesign(k = 20, #number of interim analysis planned
test.type = 1, # for one-sided tests
delta = 0, # default effect size
alpha = 0.05, #type I error rate
beta = 0.2, # type II error rate
sfu = 'OF')
crit_of <- design_of$upper$bound

Interpretations of O’Brien-Fleming correction¶
In one A/A testing simulated experiment, using unadjusted quantities:
you would reject \(H_0\): the observed (unadjusted) t-statistic is bigger than the (unadjusted) critical value
Using O’Brien-Fleming’s critical values:
you would fail to reject \(H_0\): the observed (unadjusted) t-statistic is smaller than the (adjusted) critical value
Important
The O’Brien-Fleming’s critical values are non-constant!! The test is very conservative at the beginning when less data is available and becomes less conservative as more data is collected.
Type I error rate control¶
To better understand the type I error rate control of the 3 approaches, you need to repeat the experiments many times and calculate the rate at which you erroneously reject \(H_0\).
Number of erroneous rejections among 100 experiments¶
set.seed(120)
### Run this before continuing
multiple_times_sequential_tests <- tibble(experiment = 1:100) %>%
mutate(seq_test = map(.x = experiment,
.f = function(x) incremental_t_test(n = 1000, d_0 = 0, sample_increase_step = 50,
mean_current = 200, sd_current = 50, sd_new = 50)))
typeI_rate <- multiple_times_sequential_tests %>%
mutate(reject = map_dbl(.x = seq_test, .f = function(x) sum(x$p_value<0.05) > 0)) %>%
mutate(n_reject_bonferroni = map_dbl(.x = seq_test, .f = function(x) sum(x$p_value < 0.05/20) > 0)) %>%
mutate(n_reject_pocock = map_dbl(.x = seq_test, .f = function(x) sum(x$statistic > crit_pocock) > 0)) %>%
mutate(n_reject_OF = map_dbl(.x = seq_test, .f = function(x) sum(x$statistic > crit_of) > 0)) %>%
summarise(Unadjusted = sum(reject),
Bonferroni= sum(n_reject_bonferroni),
Pocock = sum(n_reject_pocock),
OBrienFleming = sum(n_reject_OF),
expected_n_rejections = 5)
typeI_rate
| Unadjusted | Bonferroni | Pocock | OBrienFleming | expected_n_rejections |
|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 24 | 2 | 7 | 4 | 5 |
Conclusions¶
For the simulated experiments in the example above:
the type I error rate using unadjusted values was 24% (way above the planned 5% value)
the type I error rate using Bonferroni was 2% (below the planned 5% value)
the type I error rate using Pocock was 7% (above the planned 5% value)
the type I error rate using O’Brien-Flemming was 4% (slightly below the planned 5% value)
Important
Using a principled peeking procedure, the data can be sequentially analyzed and the experiment can be stopped earlier while controlling the type I error rate.
Summary and key concepts learned¶
In many A/B testing experiments, users would like to stop their experiments earlier depending on the results of interim analyses
If you make lots of comparisons, but don’t correct for it, your error rates are inflated!! Naively peeking at the data many times and stopping the experiment earlier than planned increases the probability of incorrectly rejecting the null hypothesis.
Stops must be part of the experimental design and appropriate testing methods must be used!
A possible way to control the type I error rated is to use a Bonferroni adjustment of the \(p\)-values (or equivalently the significance level or critical values). As with other multiple comparison problems, the Bonferroni’s correction in sequential analysis is very conservative and can affect the power of the test!!
The Pocock method offers a less conservative way of controlling the type I error rate in sequential testing with early stops.
The O’Brien-Fleming method offers a less conservative way of controlling the type I error rate in sequential testing with early stops.
Attention
Principled peeking is ok and even beneficial in A/B testing. The experimental design is a very important piece of any statistical analysis!