# install.packages("tidyverse")
library(tidyverse)Lecture 7B: Tibble Joins
October 14, 2025
From today’s class, students are anticipated to be able to:
Recognize how to manipulate data through a variety of tibble joins such as:
Mutating joins:
left_join(),right_join(),full_join(),anti_join()Filtering joins:
semi_join(),anti_join()
Perform binding:
bind_rows(),bind_cols()Join more than 2 tibbles
Join based on multiple conditions
Perform set operations on data:
intersect(),union(),setdiff()Join tibbles with different types of variables
Lecture Slides
Set-up
We will require the tidyverse functions for this chapter:
Overview of join functions
Note: In order to merge two tibbles, you need to have an identifier variable that has unique values for every row of observations in both tibbles.
Create two sample tibbles:
# First tibble
df1 <- tibble(ID = 1:3,
Name = c("Sophie", "Josh","Alex"))
# Second tibble
df2 <- tibble(ID = 2:4,
Age = c(20,50,31))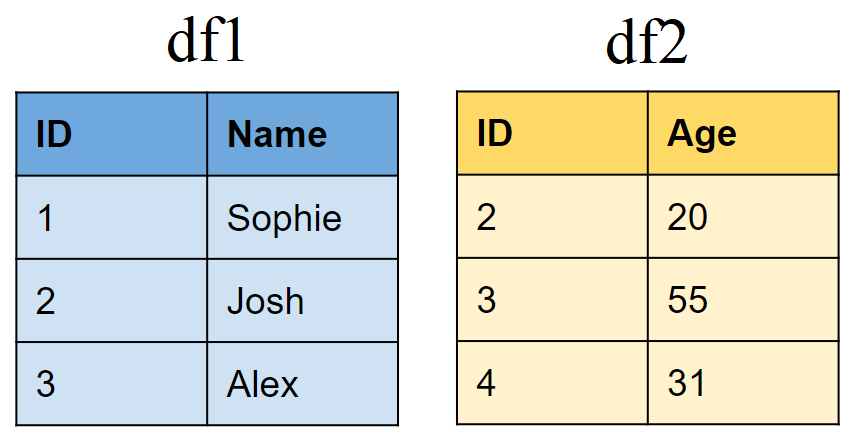
Mutating joins
Join matching rows from df2 to df1
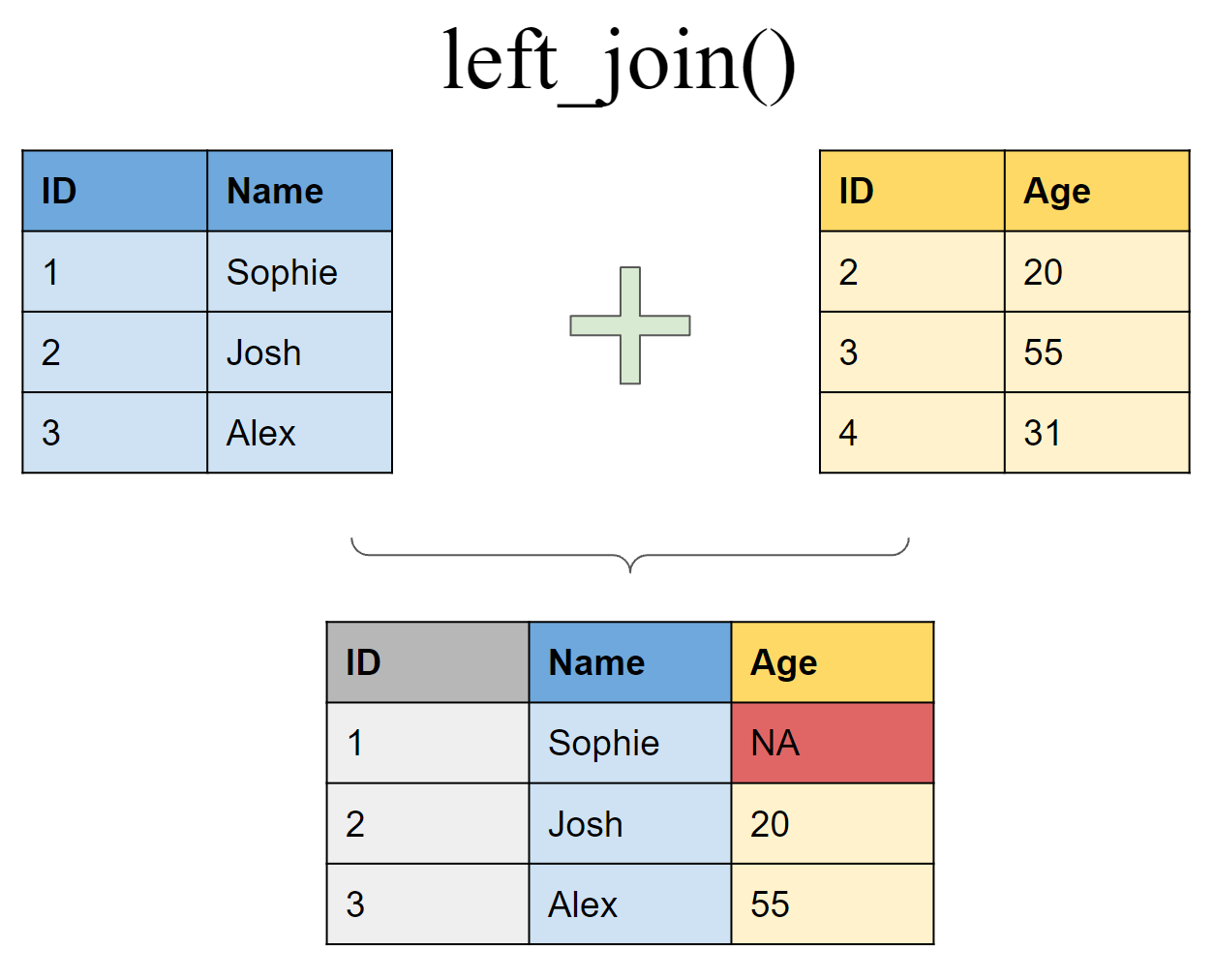
left_join(df1, df2, by = "ID")# A tibble: 3 × 3
ID Name Age
<int> <chr> <dbl>
1 1 Sophie NA
2 2 Josh 20
3 3 Alex 50Join matching rows from df1 to df2
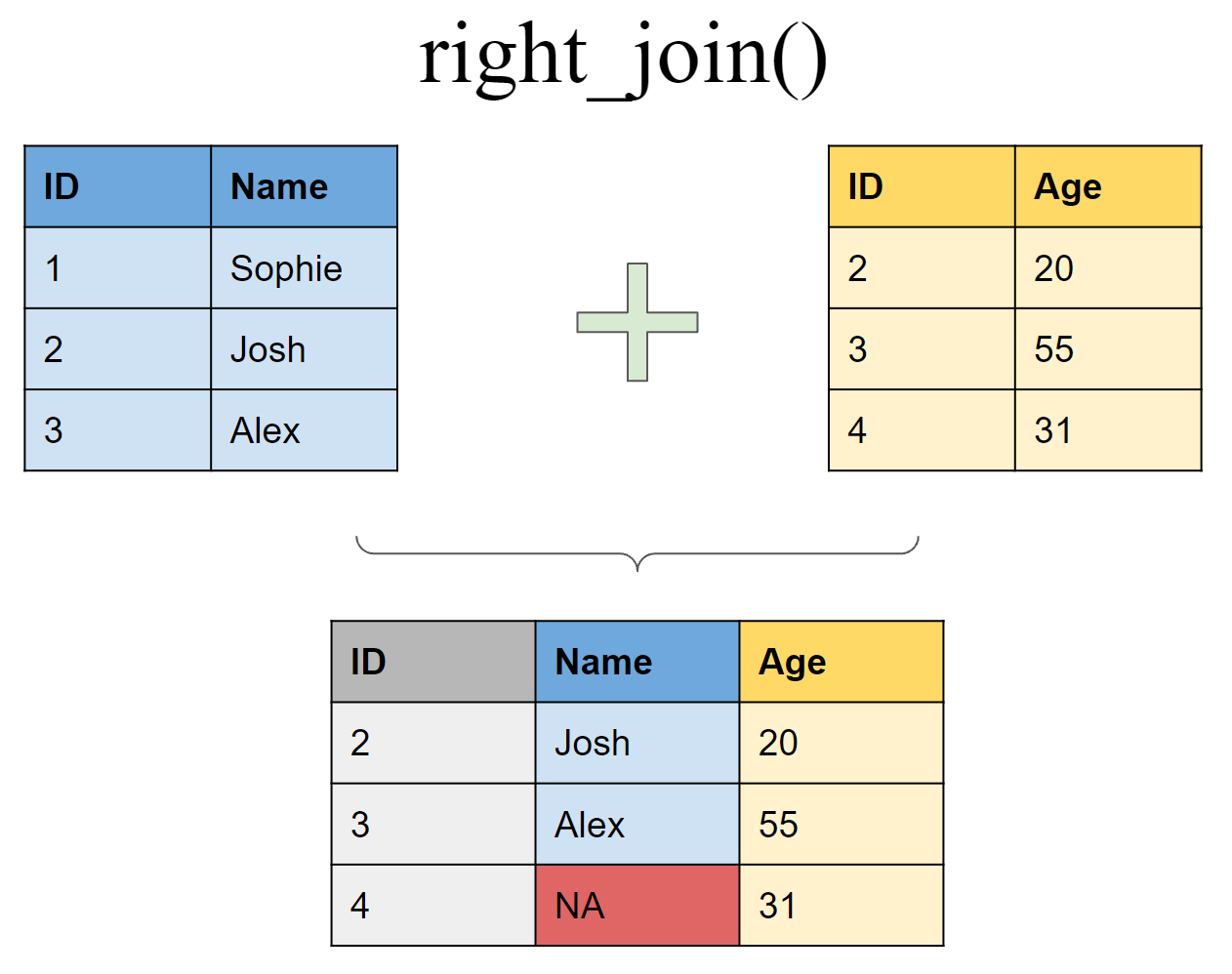
right_join(df1, df2, by = "ID")# A tibble: 3 × 3
ID Name Age
<int> <chr> <dbl>
1 2 Josh 20
2 3 Alex 50
3 4 <NA> 31Retain only rows present in both sets
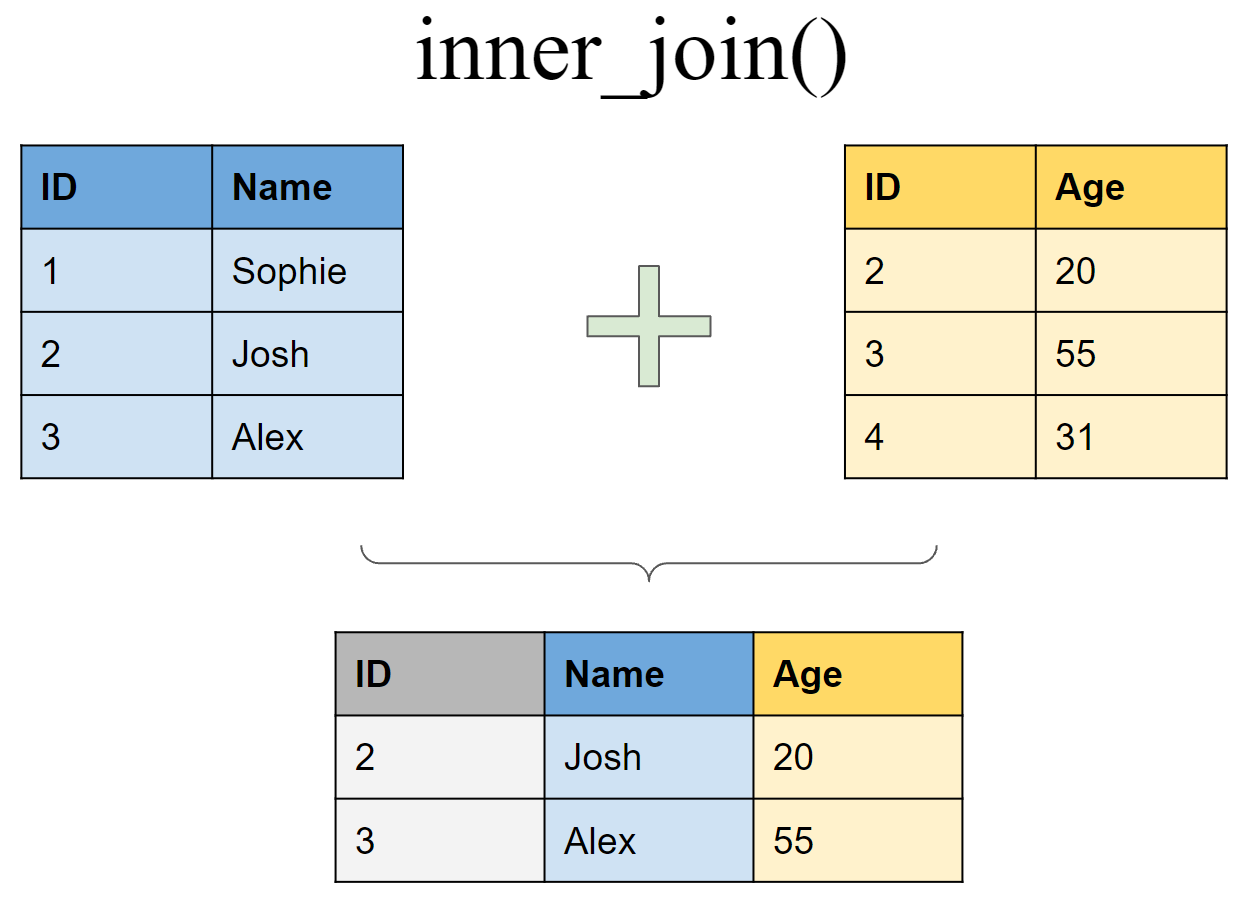
inner_join(df1, df2, by = "ID")# A tibble: 2 × 3
ID Name Age
<int> <chr> <dbl>
1 2 Josh 20
2 3 Alex 50Retain all values, all rows
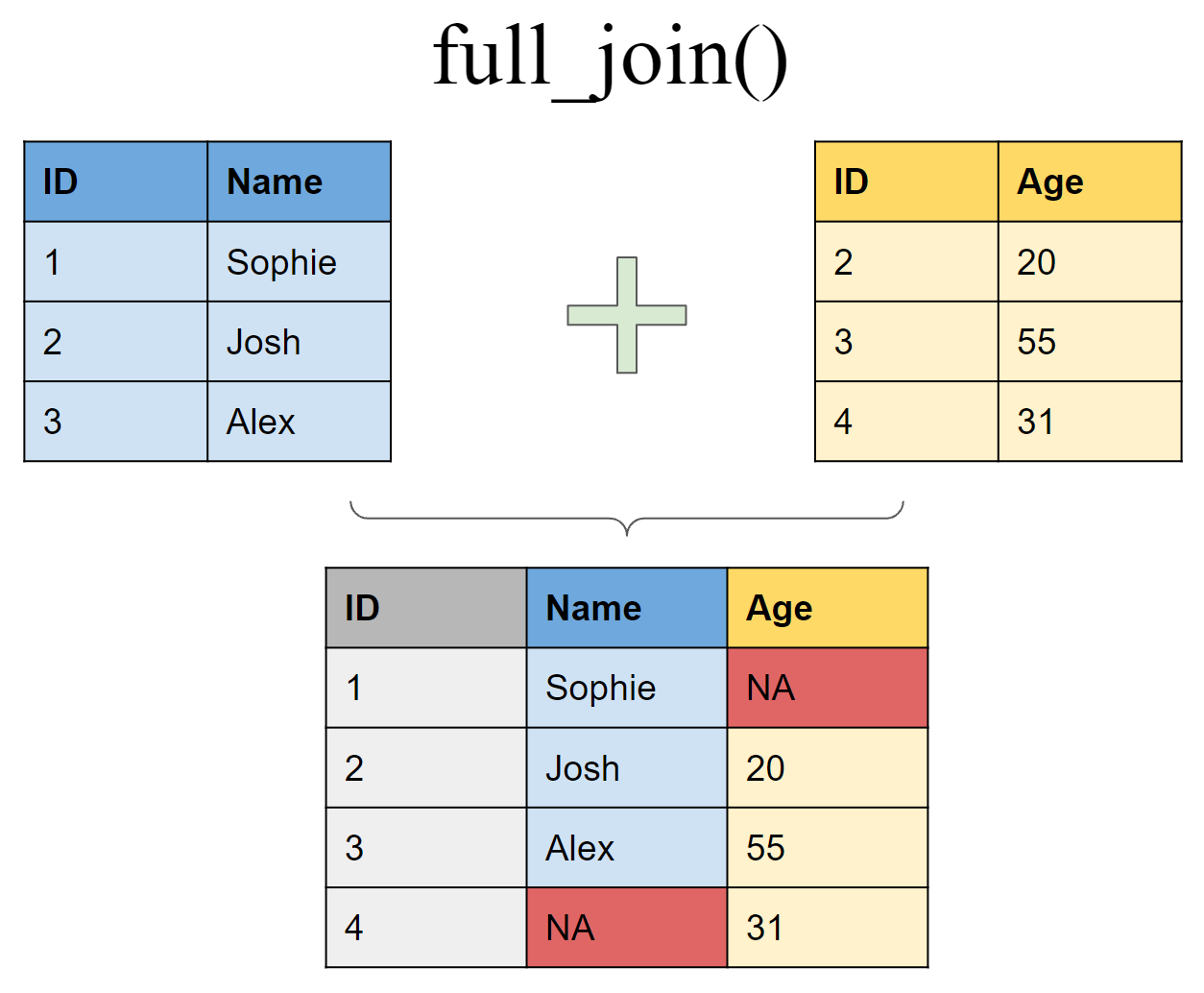
full_join(df1, df2, by = "ID")# A tibble: 4 × 3
ID Name Age
<int> <chr> <dbl>
1 1 Sophie NA
2 2 Josh 20
3 3 Alex 50
4 4 <NA> 31Filtering joins
Retain all rows in df1 that have a match in df2
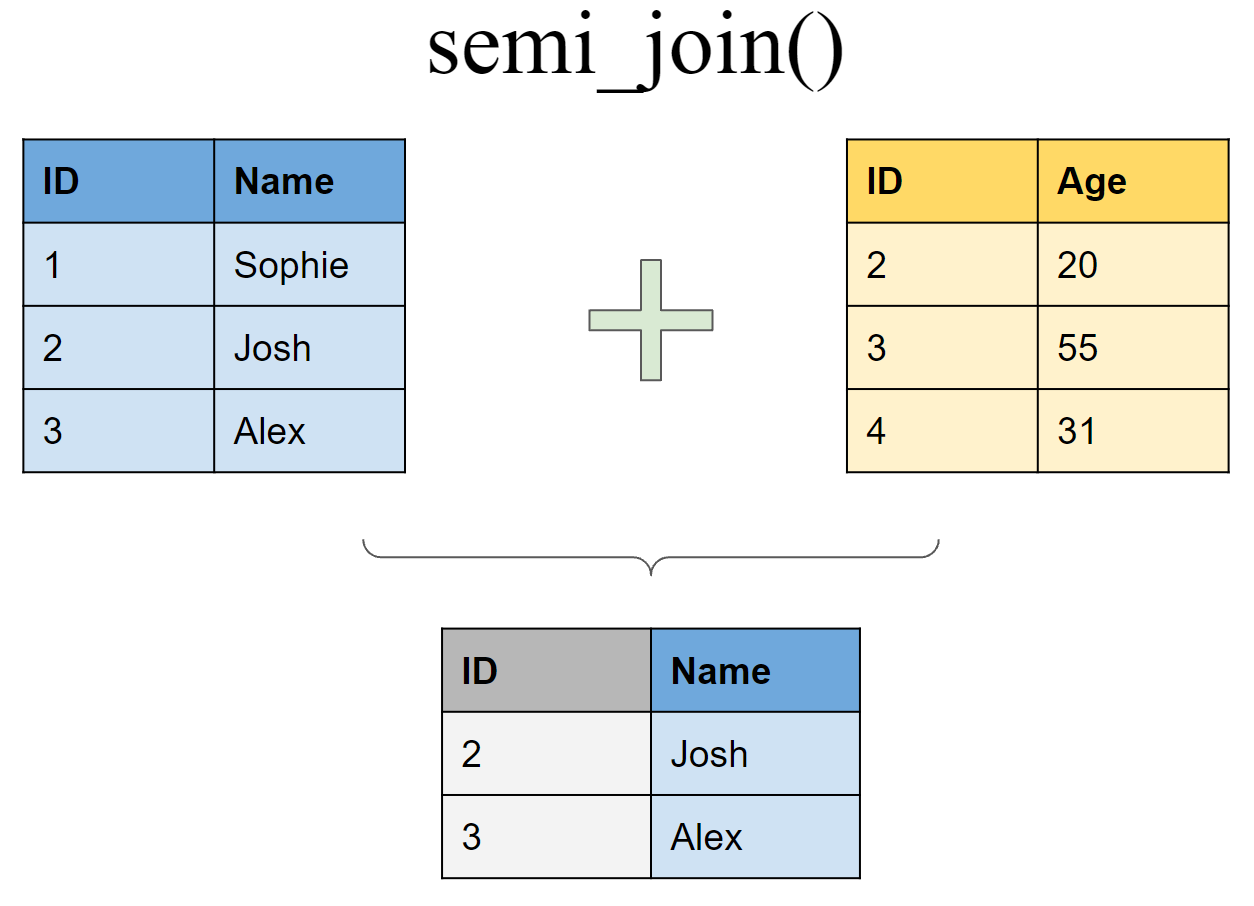
semi_join(df1, df2, by = "ID")# A tibble: 2 × 2
ID Name
<int> <chr>
1 2 Josh
2 3 Alex Retain all rows in df1 that do not have a match in df2
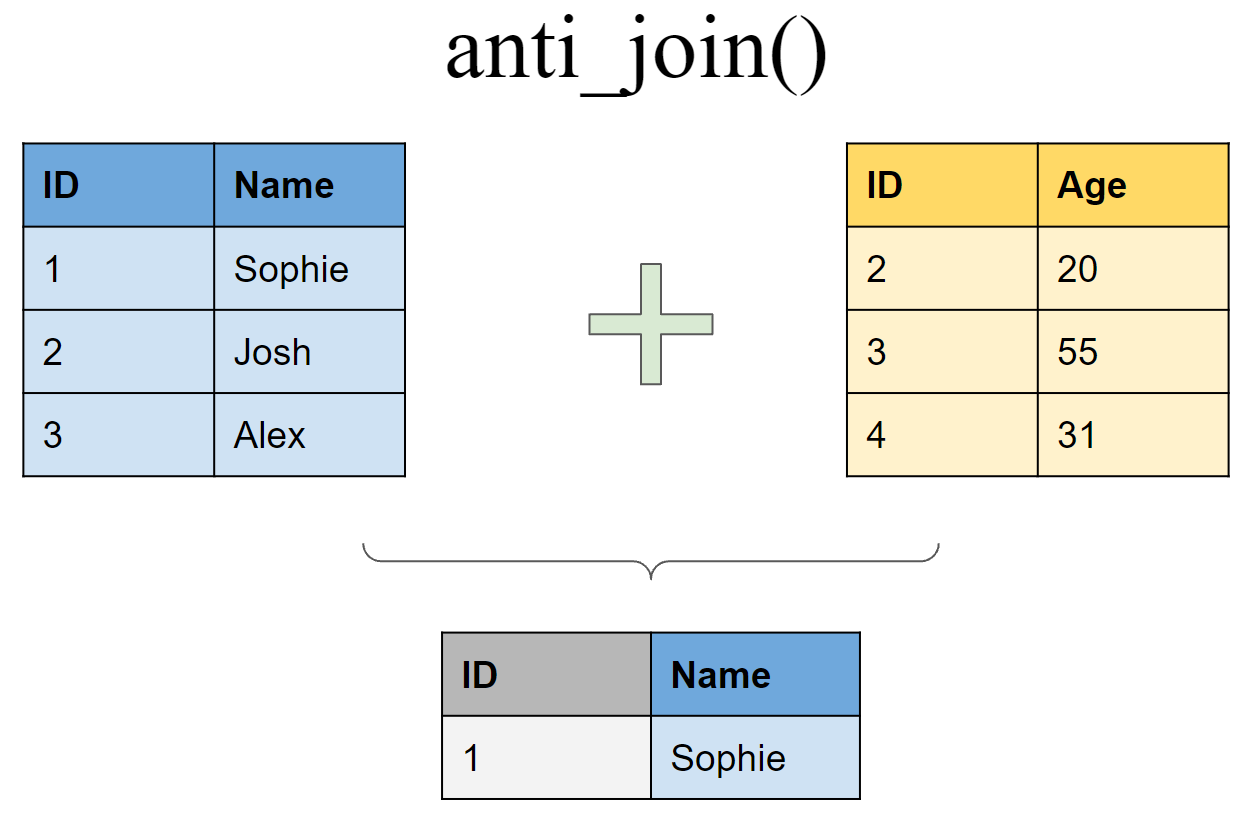
anti_join(df1, df2, by = "ID")# A tibble: 1 × 2
ID Name
<int> <chr>
1 1 SophieBinding
Append df2 to df1 as new rows
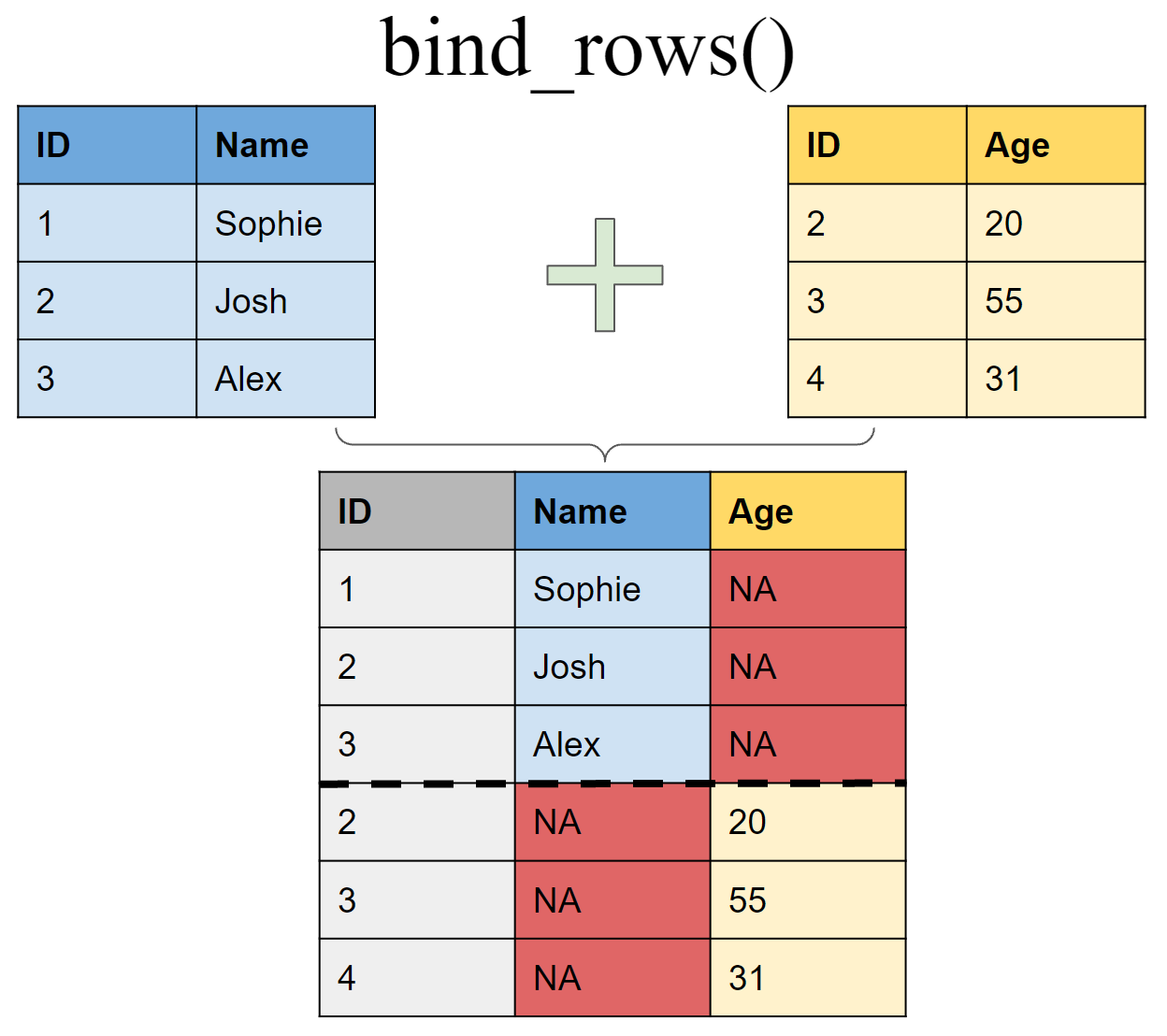
bind_rows(df1, df2)# A tibble: 6 × 3
ID Name Age
<int> <chr> <dbl>
1 1 Sophie NA
2 2 Josh NA
3 3 Alex NA
4 2 <NA> 20
5 3 <NA> 50
6 4 <NA> 31Append df2 to df1 as new columns
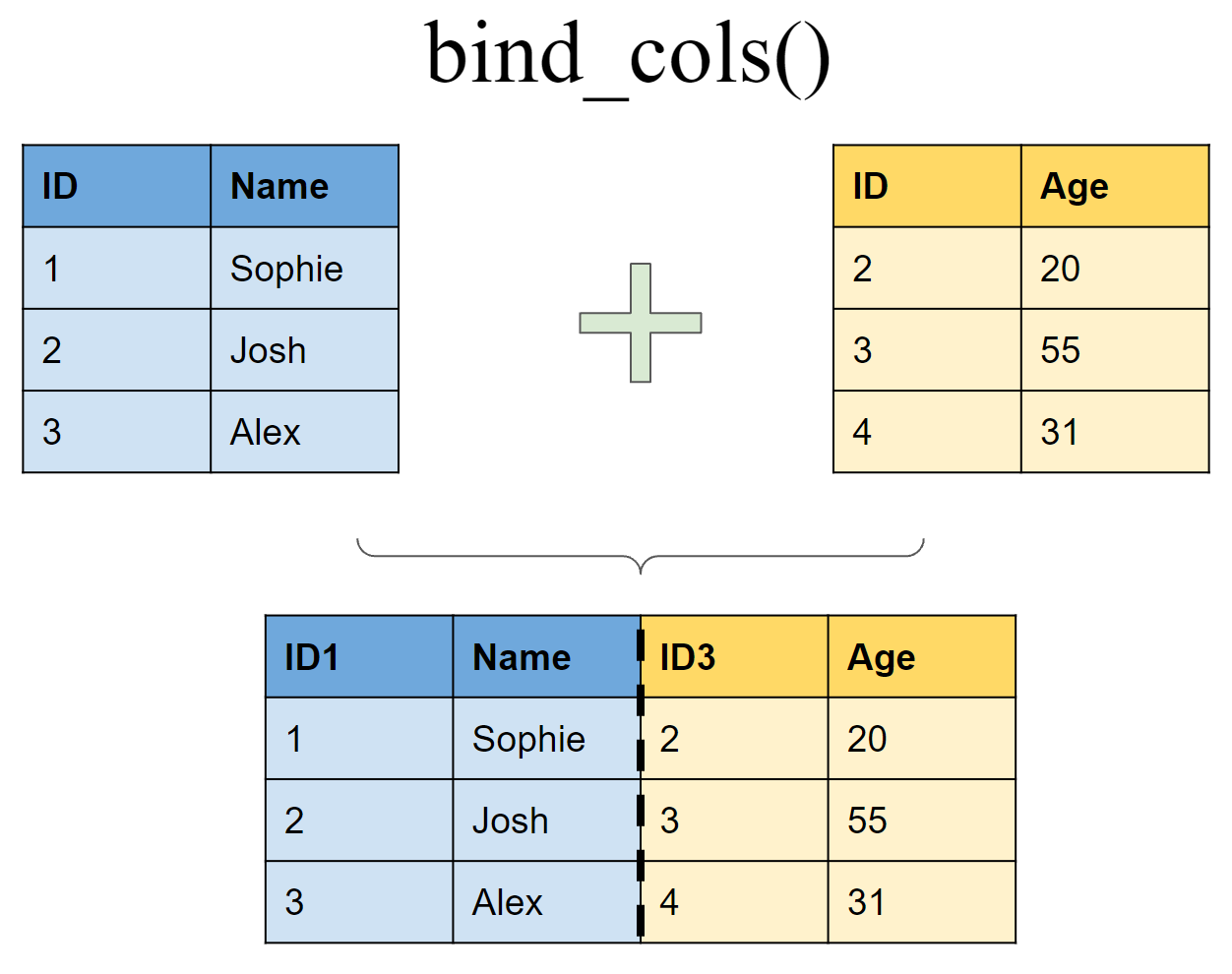
bind_cols(df1, df2)New names:
• `ID` -> `ID...1`
• `ID` -> `ID...3`# A tibble: 3 × 4
ID...1 Name ID...3 Age
<int> <chr> <int> <dbl>
1 1 Sophie 2 20
2 2 Josh 3 50
3 3 Alex 4 31Joining multiple (>2) tibbles
Create a third tibble
df3 <- tibble(ID = 1:5,
Height = c(175,167,190,155,160))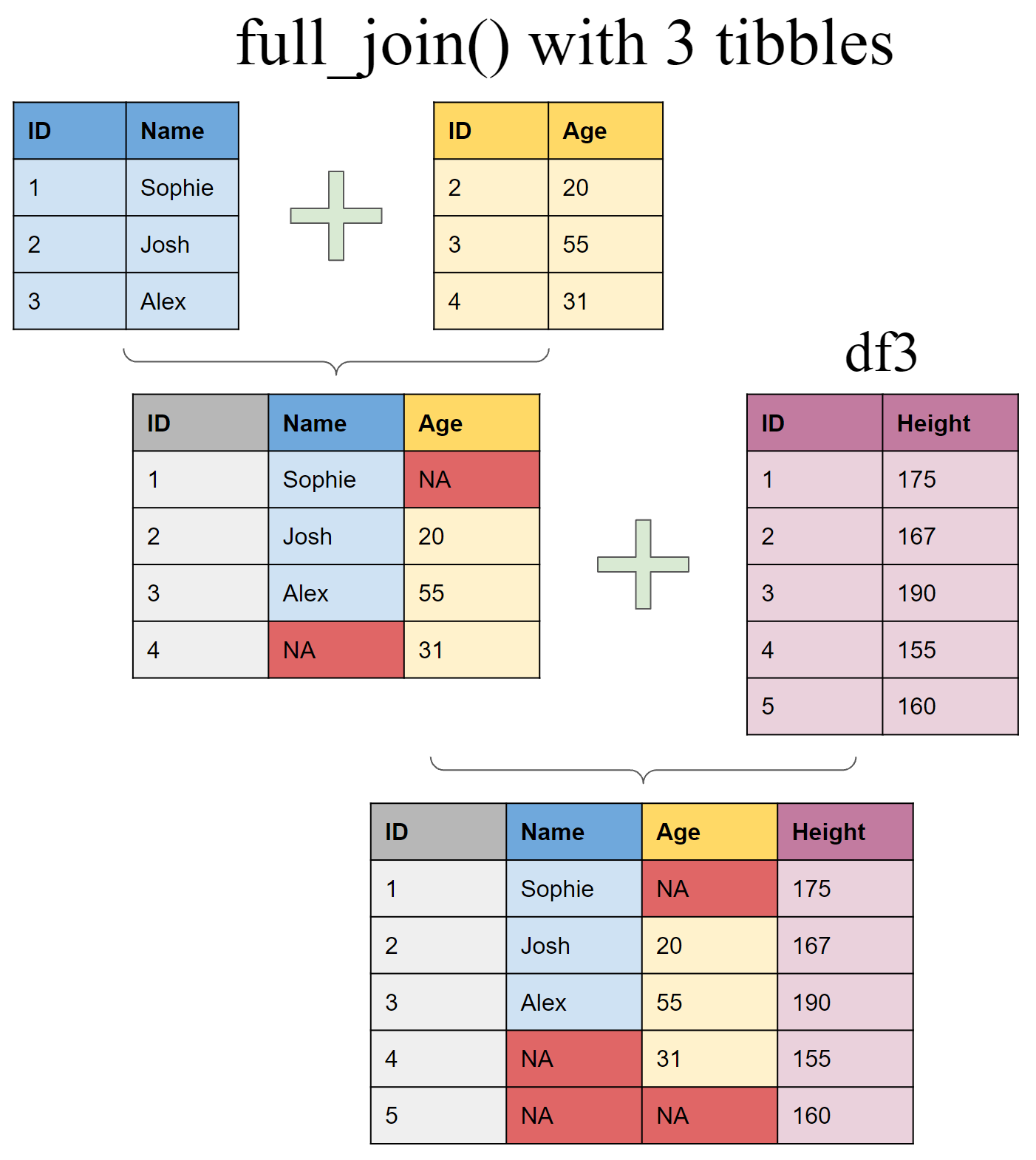
Use piping operator (%>%) to layer multiple join functions
full_join(df1, df2, by = "ID") %>%
full_join(df3, by = "ID") # A tibble: 5 × 4
ID Name Age Height
<int> <chr> <dbl> <dbl>
1 1 Sophie NA 175
2 2 Josh 20 167
3 3 Alex 50 190
4 4 <NA> 31 155
5 5 <NA> NA 160Joining tibbles on multiple conditions
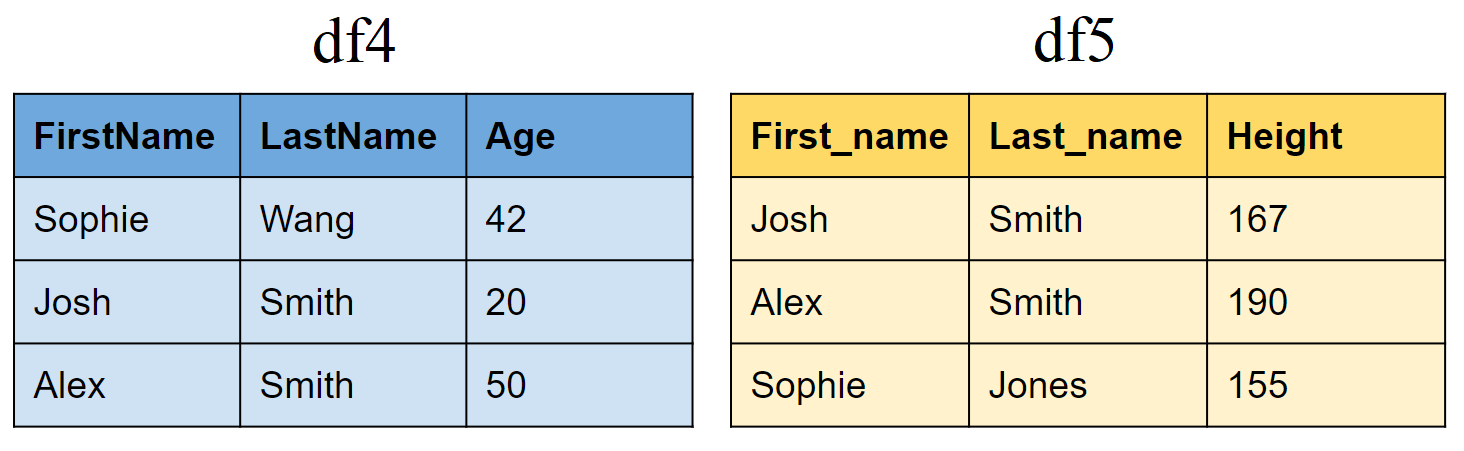
Create two new tibbles df4 and df5
df4 <- tibble(FirstName = c("Sophie", "Josh","Alex"),
LastName=c("Wang","Smith","Smith"),
Age = c(42,20,50))
df5 <- tibble(First_name = c("Josh","Alex","Sophie"),
Last_name=c("Smith","Smith","Jones"),
Height = c(167,190,155))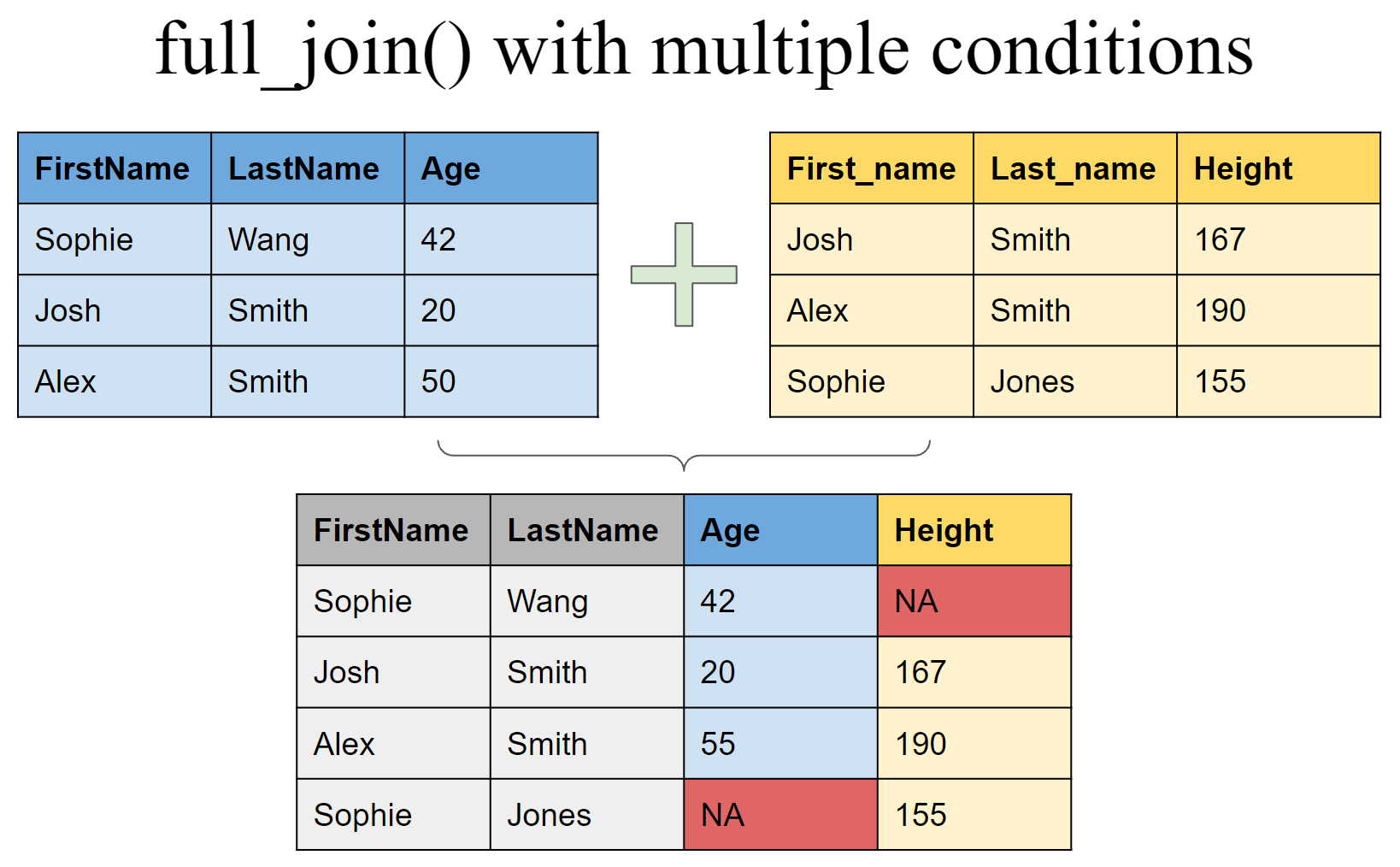
full_join(df4, df5, by = c("FirstName" = "First_name", "LastName" = "Last_name"))# A tibble: 4 × 4
FirstName LastName Age Height
<chr> <chr> <dbl> <dbl>
1 Sophie Wang 42 NA
2 Josh Smith 20 167
3 Alex Smith 50 190
4 Sophie Jones NA 155Set operations
Create sample tibbles
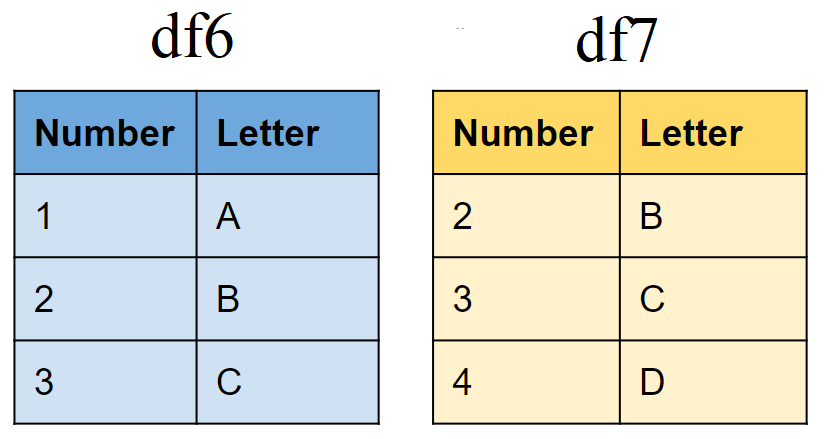
# First tibble
df6 <- tibble(Number = 1:3,
Letter = c("A", "B","C"))
# Second tibble
df7 <- tibble(Number = 2:4,
Letter = c("B","C","D"))Include rows that appear in both tibbles
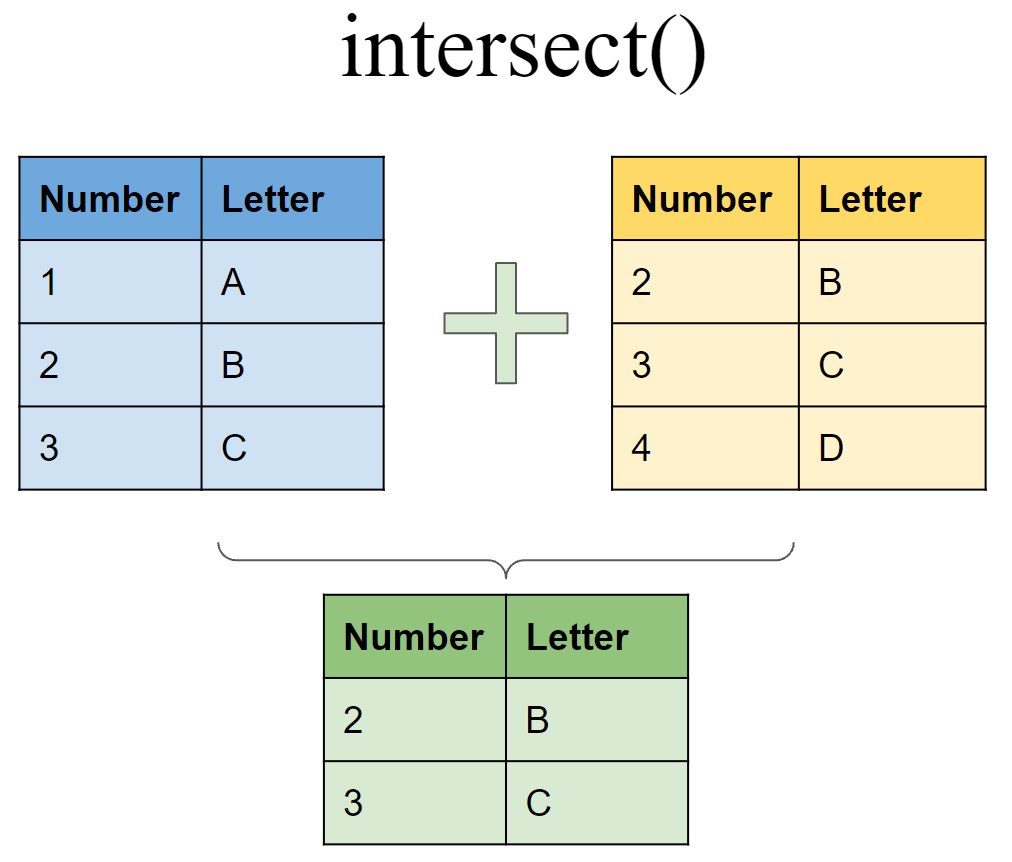
# First tibble
df6 <- tibble(Number = 1:3,
Letter = c("A", "B","C"))
# Second tibble
df7 <- tibble(Number = 2:4,
Letter = c("B","C","D"))Include rows that appear in either or both tibbles
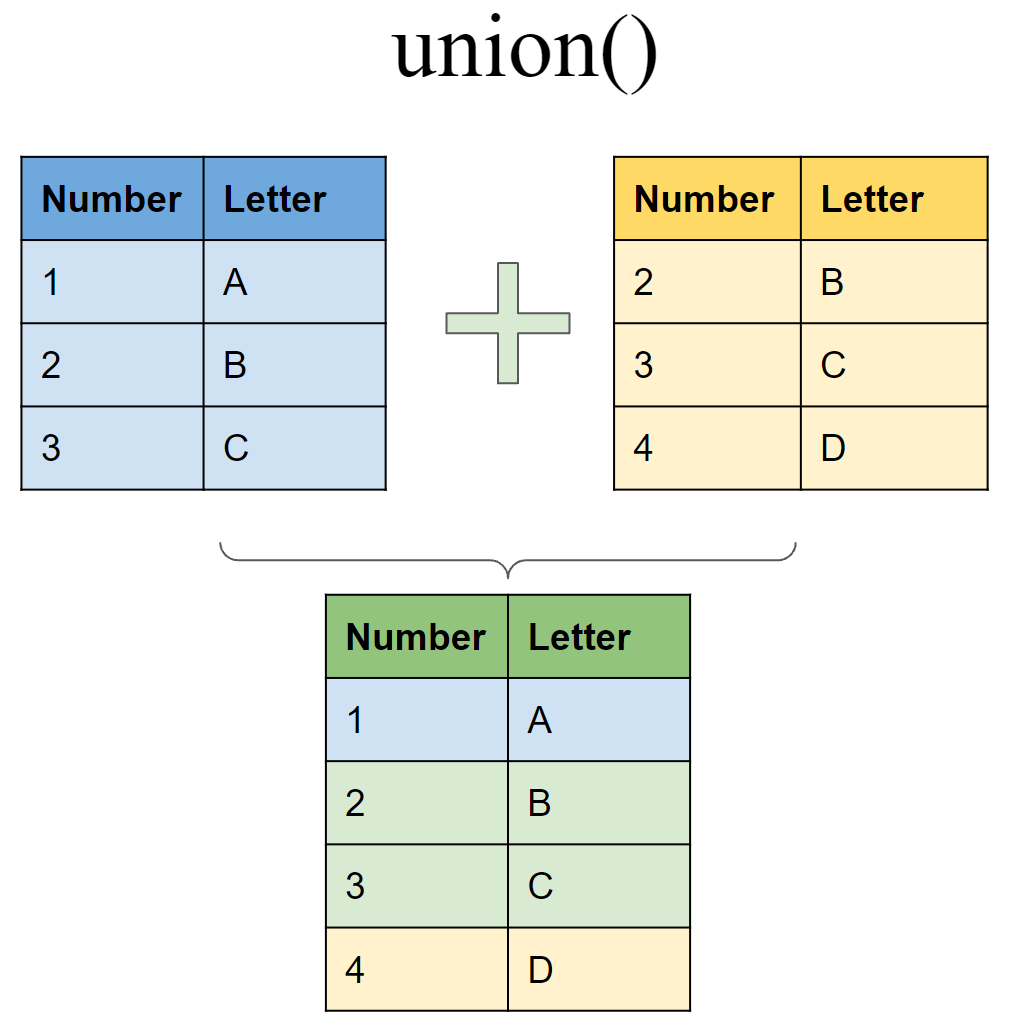
union(df6, df7)# A tibble: 4 × 2
Number Letter
<int> <chr>
1 1 A
2 2 B
3 3 C
4 4 D Include rows that appear in one tibble/dataset but not another
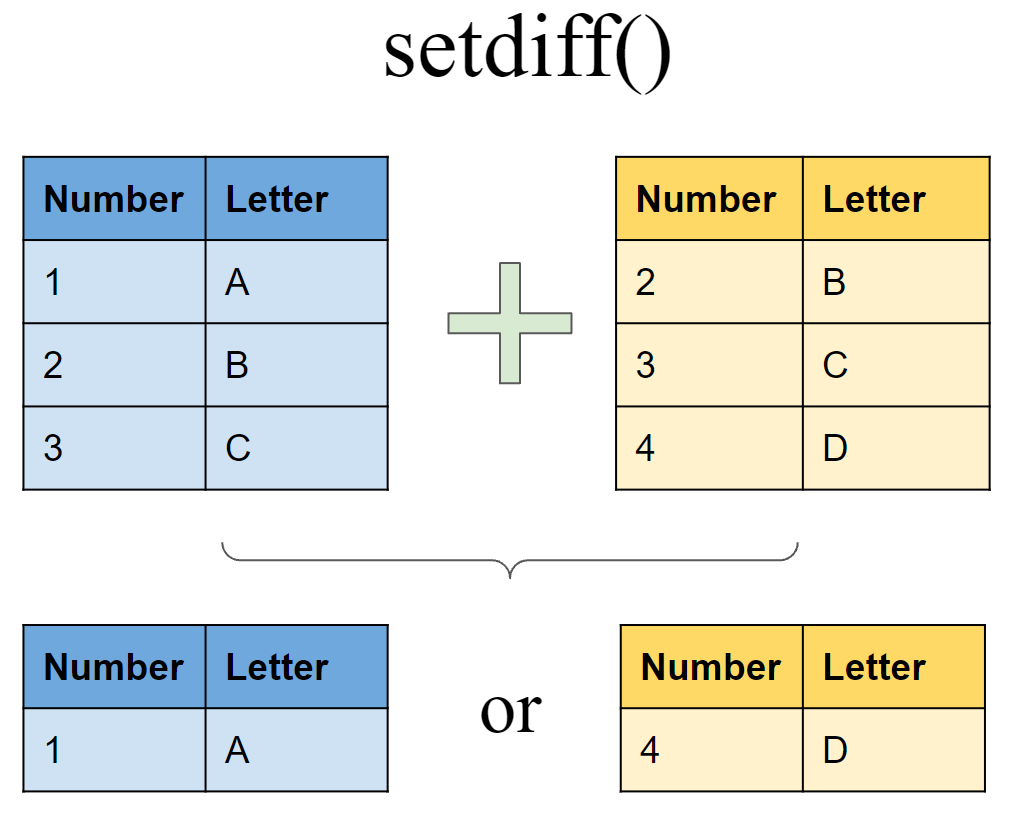
Include rows that appear in df6 but not in df7
setdiff(df6, df7)# A tibble: 1 × 2
Number Letter
<int> <chr>
1 1 A Include rows that appear in df7 but not in df6
setdiff(df7, df6)# A tibble: 1 × 2
Number Letter
<int> <chr>
1 4 D Joining tibbles with different types of variables
You can also join tibbles with sets of predictions:
set.seed(1) #make reproducible
x <- rnorm(5) #randomly sample 5 times from a N(0,1) distribution
model1 <- tibble(x = x, yhat = 2.1 + 3.2 * x) #do prediction based on the linear function
model2 <- tibble(x = x, yhat = 1.5 + 2.9 * x)
left_join(model1, model2, by = "x")# A tibble: 5 × 3
x yhat.x yhat.y
<dbl> <dbl> <dbl>
1 -0.626 0.0953 -0.317
2 0.184 2.69 2.03
3 -0.836 -0.574 -0.923
4 1.60 7.20 6.13
5 0.330 3.15 2.46 Worksheet A5
Try your hand at basics of tibble joins by working through the corresponding part of Worksheet A5.
There will be some class time to go over solutions if you got stuck on any questions.
Resources
Video lecture: Tibble Joins with dplyr
“Relational Data” chapter in “R for Data Science”.
“Two-table verbs” vignette gives a concise overview of tibble joins with dplyr.
Jenny’s Join Cheatsheet for a quick reference to joins.
dplyr cheatsheet for all these concepts packed onto a sheet of paper.